Essentially, the SRP means that a single class should hold one, and only one, responsibility, leading me to the following quote:
“There should never be more than one reason for a class to change.”— Robert C. Martin, originator of the single responsibility principle
OK, but why? Before answering, take a moment to remember a project you’ve worked on where someone changed one or more requirements along the way. I recall several projects that would have benefited from this principle. Now, imagine how much simpler it would have been if each part of your system had just one job: one reason to change.
Software maintainability problems can be due to both tech and non-tech people. Nothing is purely black or white—most things are a shade of gray. The same applies to software design: always do your best, learn from your mistakes, and stay humble (a.k.a. continuous improvement).
By understanding that applications are born to change, you will feel better when that happens, while the SRP helps mitigate the impact of changes. For example, it helps make our classes more readable and reusable and to create more flexible and maintainable systems. Moreover, when a class does only one thing, it’s easier to see how changes will affect the system, which is more challenging with complex classes since one change might break other parts. Furthermore, fewer responsibilities mean less code. Less code is easier to understand, helping you grasp that part of the software more quickly.Let’s try this out in action.
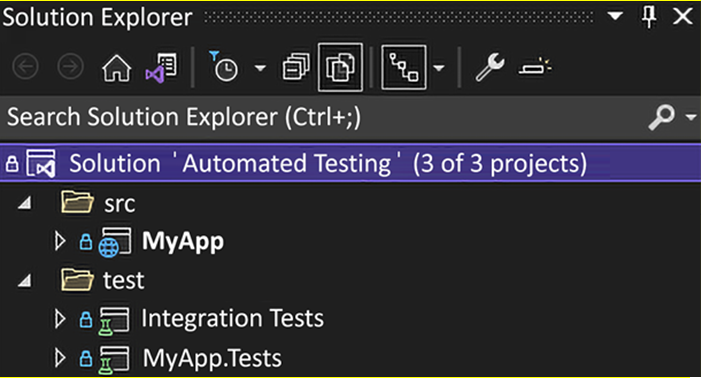
Project – Single Responsibility
First, we look at the Product class used in both code samples. That class represents a simple fictive product:
public record class Product(int Id, string Name);
The code sample has no implementation because it is irrelevant to understanding the SRP. We focus on the class API instead. Please assume we implemented the data-access logic using your favorite database.
The following class breaks the SRP:
namespace BeforeSRP;
public class ProductRepository
{
public ValueTask<Product> GetOnePublicProductAsync(int productId)
=> throw new NotImplementedException();
public ValueTask<Product> GetOnePrivateProductAsync(int productId)
=> throw new NotImplementedException();
public ValueTask<IEnumerable<Product>> GetAllPublicProductsAsync()
=> throw new NotImplementedException();
public ValueTask<IEnumerable<Product>> GetAllPrivateProductsAsync()
=> throw new NotImplementedException();
public ValueTask CreateAsync(Product product)
=> throw new NotImplementedException();
public ValueTask UpdateAsync(Product product)
=> throw new NotImplementedException();
public ValueTask DeleteAsync(Product product)
=> throw new NotImplementedException();
}
What does not conform to the SRP in the preceding class? By reading the name of the methods, we can extract two responsibilities:
- Handling public products (highlighted code).
- Handling private products.